
This article covers
Genetic code
Our genes are encrypted books carrying the secrets of life. In order to understand these secret messages, we would need to know the code and apply the same set of rules, in reverse, to decode it. In this article, we’ll take a closer look at the genetic code, which allows DNA and RNA sequences to be “decoded” into the amino acids of proteins.

How do our cells make proteins – Transcription and Translation
Our genes are written as the nucleotide base pairs (A, T, G, C) in the DNA. For a gene to exert its function, the genetic information must read out to build a protein. This process is called gene expression.
There are two steps for making proteins from genes:
First, inside the nucleus, a process that makes copies of a certain gene in the form of massager RNAs (mRNAs), called transcription.
Second, these mRNAs are exported outside of the nucleus to the cytoplasm for ribosomes to make polypeptides/ proteins. This step is called translation.
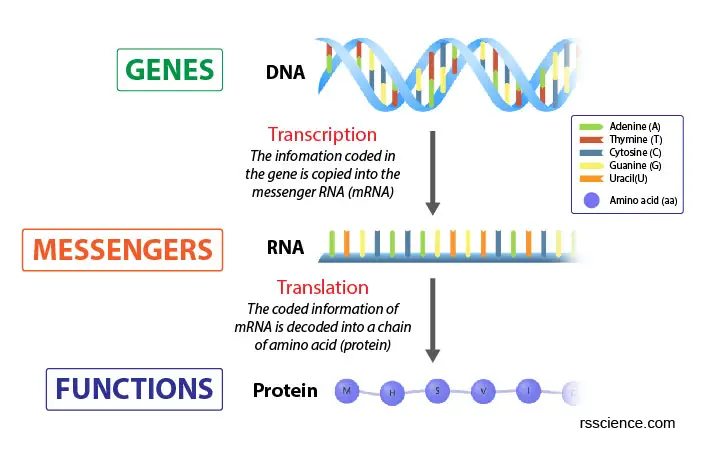
[In this image] The Central Dogma of Biology.
Genes contain the information to build proteins that maintain cell viability. This building process is done in 2 steps: Transcription and Translation.
The copy from DNA to RNA is simple: following the complementary base pairing rule. In DNA, there are four nitrogenous base options: Adenine (A), Thymine (T), Cytosine (C), and Guanine (G). Each base can only bond with one other, A with T and C with G. This is called the DNA complementary base pairing rule.
To transcript DNA into mRNA, the rule is the same. The only difference is that Uracil (U) replaces Thymine (T). So, G ↔ C, A → U, and T → A. In our cell, the transcription is done by an enzyme called RNA polymerase in the nucleus, which can synthesize mRNA from a DNA template.
DNA to mRNA: Using complementary base pairing rules
Knowing this rule, you can figure out the complementary strand to a single DNA strand based only on the base pair sequence. For example, let’s say you know the sequence of one DNA strand that is as follows:
DNA (coding strand): 5’-TTG ACG ACA AGC TGT TTC-3’
Using the complementary base pairing rules, you can conclude that the complementary strand is:
DNA (template strand): 3’-AAC TGC TGT TCG ACA AAG-5’
RNA strands are also complimentary with the exception that RNA uses U instead of T. Therefore, you can also infer the mRNA strand that would be produced from the first DNA strand. It would be:
mRNA: 5’-UUG ACG ACA AGC UGU UUC-3’
RNA to Protein: Using genetic codons
While DNA (genes) and RNA (messengers) use similar codes made of 4 units, proteins are built very differently. Proteins are built using 20 units called amino acids. Translating mRNA to protein becomes much more complicated. To guide this translation, cells follow the genetic code. According to the genetic code, the genetic information is organized in triplets of nucleotides, and each triplet is translated into one amino acid.
For example, the mRNA above will translate into
Protein: Leu – Thr – Thr – Ser – Cys – Phe
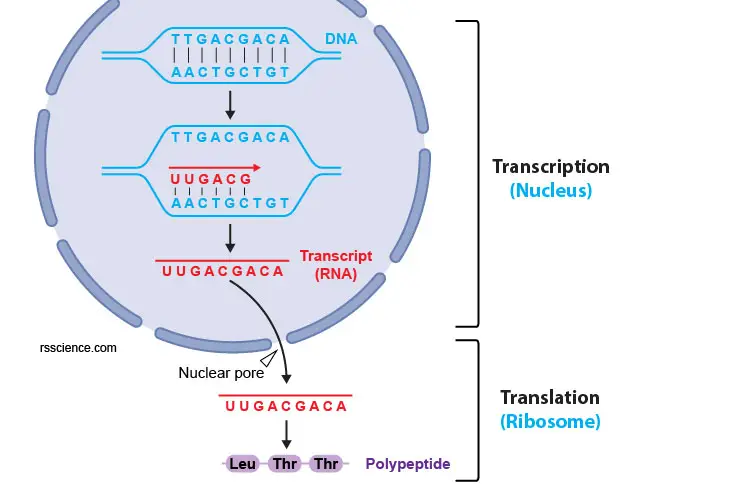
[In this figure] The process of gene expression. From a gene to a protein, there are two steps, transcription and translation. The DNA needs to be transcripted to mRNA using complementary base pairing (i.e., A pairs with U; T pairs with A; C pairs with G; G pairs with C). Next, the mRNAs are exported to the cytoplasm through nuclear pores and are translated to proteins by ribosomes.
Note: A short chain of amino acids is often referred to as a “polypeptide”. When the number of amino acids adds up (usually > 30 units) and the polypeptide chain folds into a 3D structure, we call it a “protein”.
There are three features of codons:
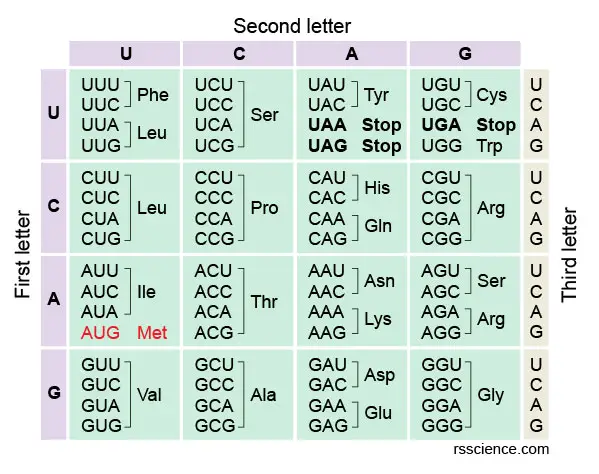
- Each codon specifies an amino acid. The full set of relationships between codons and amino acids is summarized as a Condon Chart or Table.
- One “Start” codon (AUG) marks the beginning of a protein. AUG encodes the amino acid, called Methionine.
- Three “Stop” codons mark the end of a protein and terminate the translation.
Who can read these codes? Ribosome as a decoding machine
Codons in an mRNA are read by a ribosome during translation. A ribosome is a particle-like cell organelle made of ribosomal RNA (rRNA) and ribosomal proteins. A ribosome consists of two major components: the small and large ribosomal subunits. Three binding sites for tRNA (A, P, and E sites) between the two subunits. Read more about ribosomes.
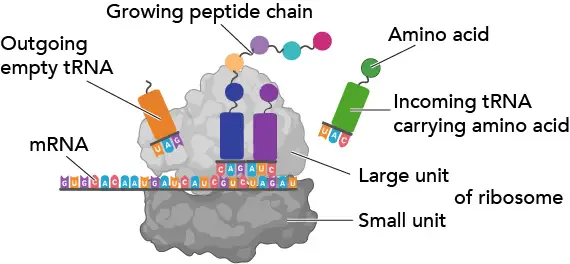
[In this figure] Ribosome.
Ribosomes work like decoding machines to translate the code sequence of mRNA into a protein. Scientists like to call ribosomes, the molecular micro-machines, to admire how exquisite the ribosomes’ design is!
Transfer RNA (tRNA)
The transfer RNA (tRNA) is one type of RNA molecule. Its job is to carry the amino acid that matches the mRNA codon to the ribosome.
The tRNA contains a three-letter code on one side and carries a specific amino acid on the other side. The code on tRNA (called an anticodon) must match the three-letter code (the codon) on the mRNA already in the ribosome. The particular amino acid that tRNA carries is determined by a three-letter anticodon it bears. For example, if the three-letter code is AUG on mRNA, the tRNA that carried Methionine (Met) will be selected and recruited to the ribosome. This is an essential part of the translation process, and it is surprising how few “errors of translation” occur.
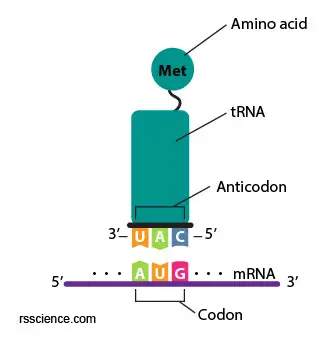
[In this figure] A anticodon UAG on the tRNA matches to the AUG on the mRNA (complimentary) and bring the right amino acid (Methionine) to the ribosomes.
Protein translation begins with a start codon (always AUG → Methionine) and continues until a stop codon (any one of the three: UAA, UAG, or UGA) is reached. mRNA codons are read from 5′ end to 3′ end, and its order specifies the order of amino acids in a protein from N-terminus to C-terminus.
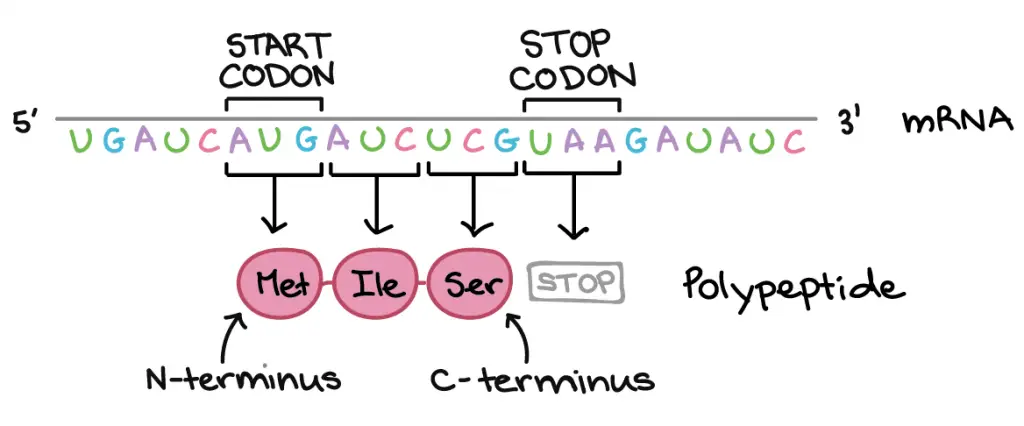
[In this figure] Directionality: DNA and RNA read from 5’ end to 3’ end. Instead, proteins or polypeptides read from N-terminus (amino group) to C-terminus (carboxyl group). The beginning and the end of a translation is marked by the Start and Stop codons, respectively.
Photo credit: khanacademy
The amino acids codon chart
The full set of relationships between codons and amino acids (or stop signals) is called the genetic code. The genetic code is often summarized in a codon chart (or codon table), where codons are translated to amino acids.

[In this image] Condon set can also be presented as a codon wheel.
Photo credit: wiki
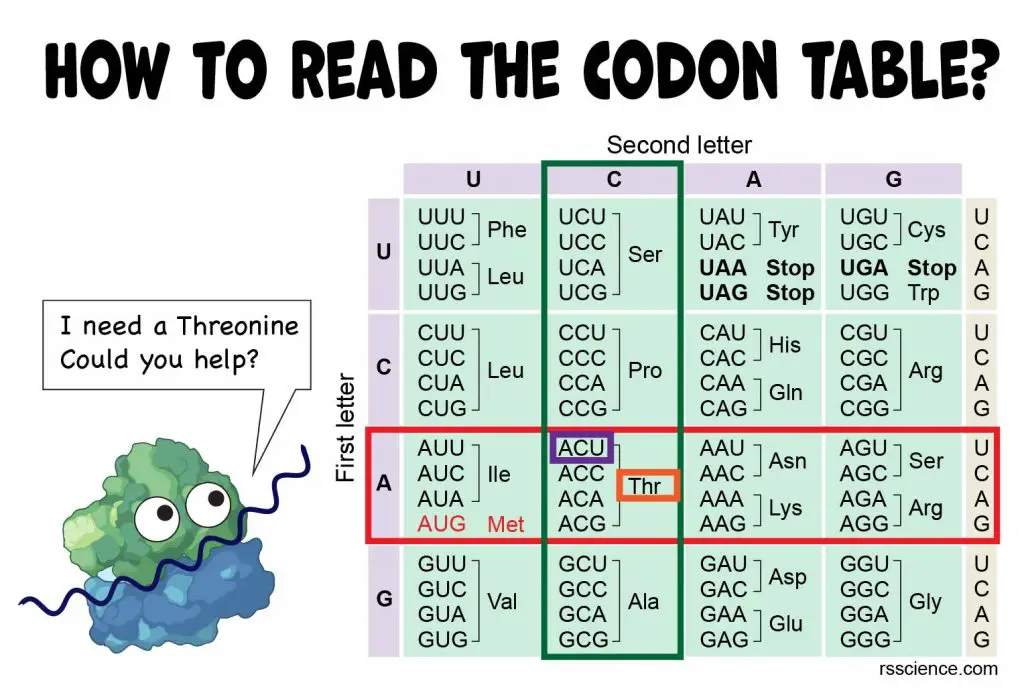
How do you read the codon chart?
The codon chart may look intimidating at first. In fact, it is not difficult at all once you understand its rule.
Let’s take codon ACU as an example. If you want to know which amino acid ACU encodes, you first look at the left side of the table. Find the “A” on the axis of the left side, which refers to the first letter of the codon triplet. All these codons starting with “A” are in this row.
Next, we look at the top of the table. This upper axis indicates the second letter of the codon triplet. Once we find “C along the upper axis, it tells us about the column in which our codon will be found. Find the intersecting box of “A” row and “C” column in the table. You will see this box containing four codons and easily find the one you’re looking for.
In our example, ACU encodes Thr (or Threonine). You may also notice that all ACU, ACC, ACA, and ACG encode the same amino acid. Notice that many amino acids are represented in the table by more than one codon. For instance, there are six different ways to “write” Leucine in the language of mRNA (see if you can find all six).
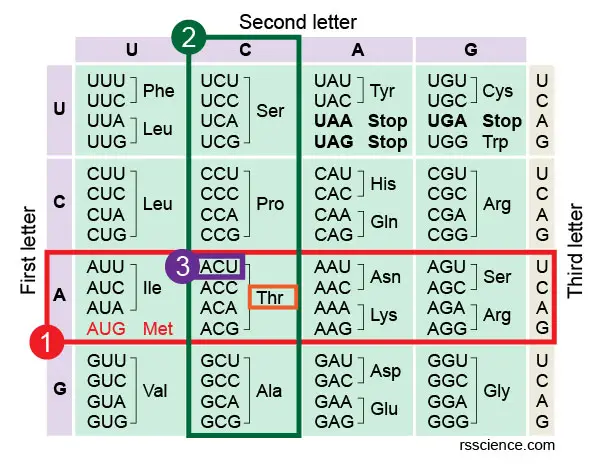
[In this image] How to read the amino acids codon chart?
Following Step 1-3 to find the codon triplet in the table.
In this table, you can also see that UAA, UAG, and UGA do not encode any amino acid, meaning they are stop codons.
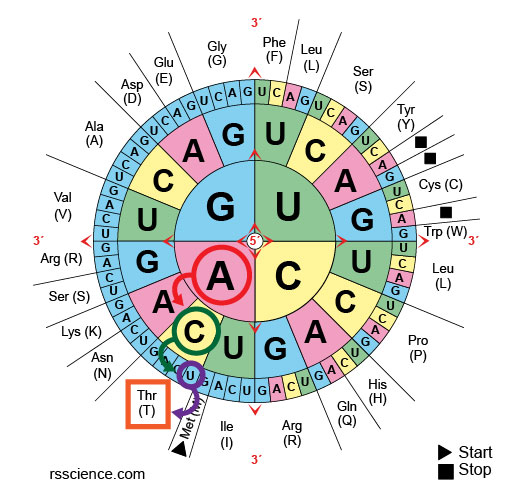
[In this image] For a codon wheel, the rule is the same: start from the center to find the first letter of triplet, then move toward the periphery for 2nd and 3rd letters.
You and your family or classroom can play the “Codon Bingo” to get familiar with the genetic code. Here is a downloadable version.
Reference Table: a summary of all amino acids codons
| Amino Acid | Codon |
| Phenylalanine (Phe) | UUU, UUC |
| Leucine (Leu) | UUA, UUG, CUU, CUC, CUA, CUG |
| Methionine (Met) / Start Codon | AUG |
| Valine (Val) | GUU, GUC, GUA, GUG |
| Serine (Ser) | UCU, UCC, UCA, UCG, AGU, AGC |
| Proline (Pro) | CCU, CCC, CCA, CCG |
| Threonine (Thr) | ACU, ACC, ACA, ACG |
| Alanine (Ala) | GCU, GCC, GCA, GCG |
| Tyrosine (Tyr) | UAU, UAC |
| Histidine (His) | CAU, CAC |
| Glutamine (Gln) | CAA, CAG |
| Asparagine (Asn) | AAU, AAC |
| Lysine (Lys) | AAA, AAG |
| Aspartic Acid (Asp) | GAU, GAC |
| Glutamic Acid (Glu) | GAA, GAG |
| Cysteine (Cys) | UGU, UGC |
| Tryptophan (Trp) | UGG |
| Arginine (Arg) | CGU, CGC, CGA, CGG, AGA, AGG |
| Glycine (Gly) | GGU, GGC, GGA, GGG |
| Isoleucine (Ile) | AUU, AUC, AUA |
| Stop Codon | UAA, UAG, UGA |
Molecular structures of Amino acids
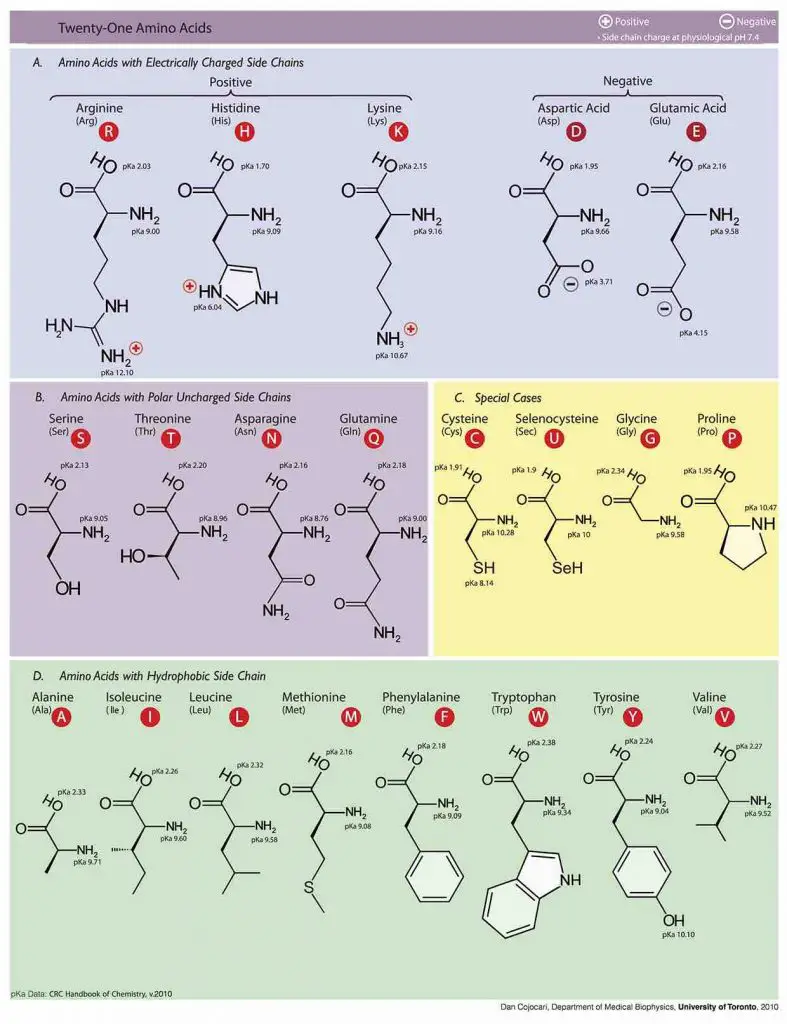
Photo source: wiki
Standard Genetic Code
The genetic code we mentioned here is universal; with only a few exceptions, virtually all species (from bacteria to humans) use the same set of standard code. Some ciliates, such as Paramecium bursaria, use unusual genetic code.
Another exception is mitochondrial DNA. Mitochondria have their own copies of DNA as well as an independent system of ribosomes and tRNAs. If you are not familiar with mitochondria, click here to learn more about mitochondria.
The mitochondrial code is slightly different from the standard genetic code. Moreover, different species have their own versions of mitochondrial codes. For example, our (vertebrate) mitochondrial code is different from the one yeast uses. AGA and AGG encode Arginine (Arg) in the standard genetic code. However, AGA and AGG act as stop codons in the vertebrate mitochondrial code. In addition, UGA and AUA change from stop codon and Isoleucine (Ile) to Methionine (Met) and Tryptophan (Trp), respectively, in mitochondria.
The same situation also happens in the plant’s chloroplast and plastid codes.
Codon usage biases
Although most organisms use the standard code, however, they may have their own biases in terms of choosing which codons to use. For example, baking yeasts prefer using UGU for Cysteine. In contrast, in human cells, we prefer UGC.
Codon usage biases could be the consequence of natural selection (tRNA abundance). For laboratories to produce certain proteins in a large quantity, researchers may perform “codon optimization” to resynthesize genes in such a way that their codons are more appropriate for the desired expression host (i.e., making human proteins in E coli. bacteria).
What is reading frame?
Since the DNA sequence is read by triplets, starting from which letter (or reading frame) becomes a critical problem.
Let’s look at an example. The mRNA below can be translated into three totally different orders of amino acids, depending on the frame in which it’s read. How do our cells know which of these proteins to make?
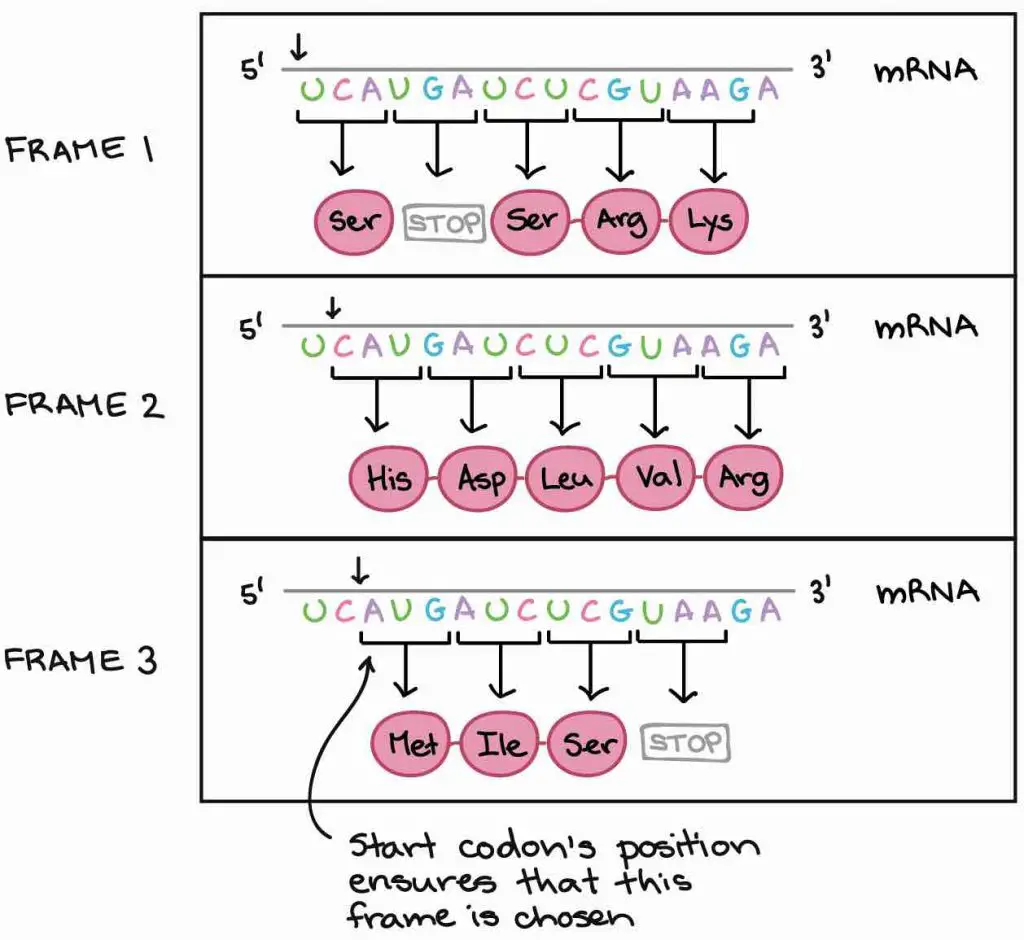
[In this image] Three possible reading frames could lead to totally different results.
Photo credit: khanacademy
Our cells use a very smart strategy to solve this problem – the “start codon”. Because the translation only begins at the start codon (AUG) and continues in successive groups of three, the position of the start codon ensures that the mRNA is read in the correct frame (in the example above, in Frame 3).
What happens if the DNA sequences are messed up – Mutation
Mutations (changes in DNA sequences) may derail the genetic information and cause cells to make the wrong proteins. Mutations are the major cause of cancers and many genetic disorders.
Even a single base pair altered (called point mutation) can cause a significant consequence. Point mutations can have one of three effects.
Silent mutation
First, the base substitution can be a silent mutation where the altered codon corresponds to the same amino acid. For example, changing from UCU to UCC has no effect since both codons equally encode Serine (Ser).
Missense mutation
Second, the base substitution can be a missense mutation where the altered codon corresponds to a different amino acid. For example, changing from UCU to UGU will turn Serine (Ser) to Cysteine (Cys). If this mutation happens in the critical region (i.e., enzymatic site) of the protein, a point mutation can mess up the whole protein function.
Nonsense mutation
Third, the base substitution can be a nonsense mutation where the altered codon becomes a stop signal. This is the worst cause because the translation will terminate too early, resulting in a truncated protein.
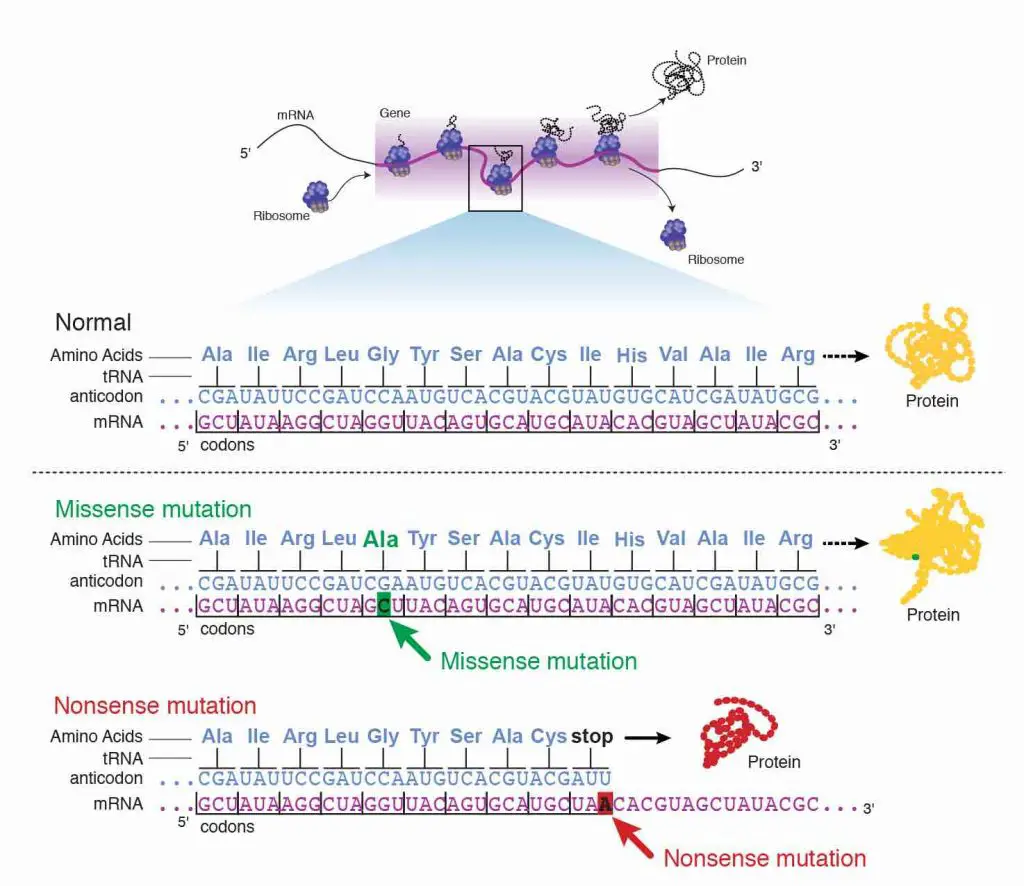
[In this image] The examples of showing the consequence of missense mutation and nonsense mutation.
Photo credit: NIH
Mutations could also happen when nucleotides are inserted or deleted from the original DNA sequence. The insertion or deletion of “one or two” nucleotides can change the reading frame (frameshift mutation). A frameshift can totally mess up the amino acid orders “downstream” the mutation site.
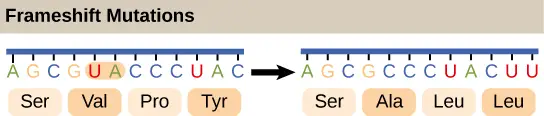
[In this image] The example of showing the consequence of frameshift mutation.
Photo credit: openstax
How was the genetic code discovered?
The understanding of genetic code is the foundation of modem biotechnology. Without the ability to read the DNA information, many exciting techniques and therapies, including personalized medicine, gene therapy, CRISPR gene editing, and recombinant protein drugs, won’t exist.
To crack the genetic code, researchers needed to figure out how nucleotides sequences in a DNA or RNA molecule could encode the sequence of amino acids. In the mid-1950s, physicist George Gamow predicted that the genetic code is likely composed of triplets of nucleotides – because the possible combination of duplet is not enough (4×4 = 16), and that of quadruplet is too many (4x4x4x4 = 256), to cover 20 kinds of amino acids.
The actual experiments to pinpoint the genetic code began in 1961 by American biochemist Marshall Nirenberg. Nirenberg was able to link the relationships between nucleotide triplets to particular amino acids by two experimental innovations:
- He can synthesize artificial mRNA molecules with specific, known sequences.
- He had a system to translate mRNAs into polypeptides outside of a cell (a “cell-free” system). Nirenberg did so in a test tube of cytoplasm from burst E. coli bacteria, which contains all the ingredients needed for translation.
Nirenberg started with an mRNA molecule consisting only of the nucleotide uracil (called poly-U). When he added poly-U mRNA to the cell-free system, he found that the polypeptides made consisted exclusively of the amino acid – Phenylalanine (Phe). Nirenberg concluded that UUU might code for phenylalanine. Using the same approach, he discovered triplet CCC codes for Proline (Pro).

Photo credit: khanacademy
Following this concept, the biochemist Har Gobind Khorana extended Nirenberg’s experiment by synthesizing artificial mRNAs with more complex sequences. By 1965, Nirenberg, Khorana, and their colleagues had deciphered the entire genetic code.
For their contributions, Nirenberg and Khorana (along with another genetic code researcher, Robert Holley) received the Nobel Prize in Physiology or Medicine in 1968.

[In this image] The Nobel Prize in Physiology or Medicine 1968 was awarded jointly to Robert W. Holley, Har Gobind Khorana, and Marshall W. Nirenberg “for their interpretation of the genetic code and its function in protein synthesis.”
Photo credit: The Nobel Prize
Website tools to convert DNA to protein
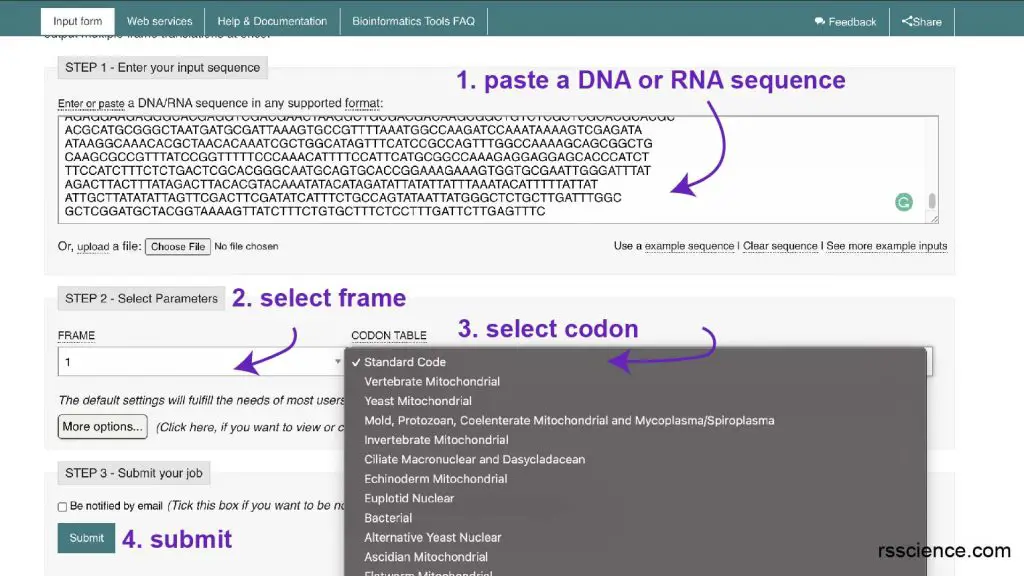
In my research that I need to clone a particular DNA for protein expression, I typically use EMBOSS Transeq from EMBL-EBI.
Step 1: Paste a piece of DNA sequence, you can use their example sequence.
Step 2: Select the reading frame you want to use
Step 3: Select codon. I typically use standard code.
Step 4: Hit submit
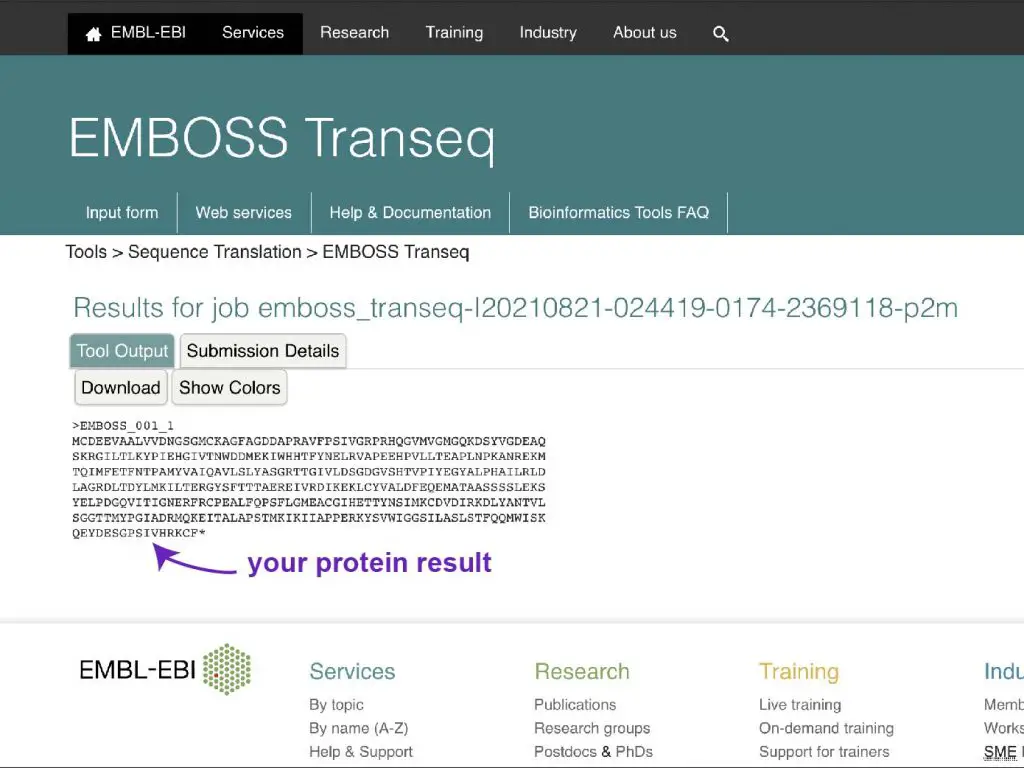
Step 5: Wait for the protein sequence result!
References
“The genetic code”
“Codon Bingo”
“The Nobel Prize in Physiology or Medicine 1968”